 The OpenAI product DALL-E 2 generated this image from the text 'artificial intelligence that kills all human life'. Hm, it looks a bit like us, doesn't it?
The OpenAI product DALL-E 2 generated this image from the text 'artificial intelligence that kills all human life'. Hm, it looks a bit like us, doesn't it?
Things are very quickly happening with artificial intelligence (AI). We get chatbots to write poetry for us, images created by typing some words, and software code delivered ready to use in our own code.
Is there some hidden cost buried here? What exactly are we paying to have all this for free?
Perhaps it's time to consider whether things are happening too quickly for the sake of humanity and other forms of lives on the planet.
Before I go into what I see as the most critical danger in technical AI development, I'll briefly touch on the hottest company in the field.
An example: OpenAI
OpenAI is a privately owned company that builds AI products for profit. Their most popular products are ChatGPT, the chatbot/virtual assistant, and DALL-E 2, AI that creates images from text.
Many people are equally flummoxed and dazzled by new AI technologies and can't understand how they, at times, seem to understand and serve us better and faster than other humans. Naturally, there are reasons for how well modern AI works.
One of the main reasons is that OpenAI products are based on data theft2. To create AI that behaves in human ways and produces material that mimics how humans act, large language models3 are used. These models are improved—or trained, in AI vernacular—by using a lot of data which is not written by OpenAI. Instead, OpenAI have stolen a lot of data. They've plundered forums, text troves, tweets, and any openly accessible stuff you can think of. For OpenAI, the ends justified the illlegal means.
Eric Schmidt, formerly CEO of Google for a decade, said something about regulation for tech companies:
In a 2010 interview with the Wall Street Journal, Schmidt insisted that Google needed no regulation because of strong incentives to ""treat its users right."8
I won't go into detail of how Google and other surveillance capitalist9 companies behave when it comes to data that belongs to individuals, but let's say this: the Cambridge Analytica10 debacle says a lot about the callousness of surveillance capitalist companies.
There are copyright lawsuits going down:
Microsoft, its subsidiary GitHub, and its business partner OpenAI have been targeted in a proposed class action lawsuit alleging that the companies’ creation of AI-powered coding assistant GitHub Copilot relies on “software piracy on an unprecedented scale.” The case is only in its earliest stages but could have a huge effect on the broader world of AI, where companies are making fortunes training software on copyright-protected data.
Copilot, which was unveiled by Microsoft-owned GitHub in June 2021, is trained on public repositories of code scraped from the web, many of which are published with licenses that require anyone reusing the code to credit its creators. Copilot has been found to regurgitate long sections of licensed code without providing credit — prompting this lawsuit that accuses the companies of violating copyright law on a massive scale.12
Other AI companies are also hit with copyright lawsuits11. Getty complain about Stable Diffusion having downloaded and used over twelve million photographs and captions to generate images that are, at times, near copies of the originals.
It's also worth to note that the word 'open' in the OpenAI company name isn't coincidental: the initial mindset at the company was all open-source, non-corporate, and non-profit. Today they're the opposite4, which bars anybody from knowing how they work and what their future plans are. It also bars their developers from working on meaningful stuff that won't generate money. While most companies don't want to be open with their future plans for a number of reasons, I'll get back to why this is bad for humanity.
OpenAI paid Kenyan workers (via San Francisco company Sama) less than 2 US Dollars per hour to make ChatGPT less heinous5. To do this, workers had to not only read vast amounts of damaging texts about, for example, pedophilia and sexism, but interact with those texts because they're working with AI systems. This was, by the way, done illegally; from the Time article:
Sama began pilot work for a separate project for OpenAI: collecting sexual and violent images—some of them illegal under U.S. law—to deliver to OpenAI.
Earlier this year, all you had to do to raise the worth of your company was to fire thousands of people7 (a lot of whom soon had to be replaced). Today, you add AI6.
AI vs human life
My prelude brings us to what I see as the most critical problem with AI: reckless companies building potentially life-threatening technology behind closed doors. Threatened by capitalist competition in the shape of 'what if we don't get there first?' type of thinking, these companies cut corners in all kinds of ways that are both unethical and illegal.
A line of famous people and unknown scholars have, through the Future of Life Institute (a think tank), recently signed an open letter1 where they ask governments to step in and enforce a pause of all AI development that's 'stronger than GPT-4' for six months. GPT-4 is a language model built by OpenAI. The letter says this:
Contemporary AI systems are now becoming human-competitive at general tasks, and we must ask ourselves: Should we let machines flood our information channels with propaganda and untruth? Should we automate away all the jobs, including the fulfilling ones? Should we develop nonhuman minds that might eventually outnumber, outsmart, obsolete and replace us? Should we risk loss of control of our civilization? Such decisions must not be delegated to unelected tech leaders. Powerful AI systems should be developed only once we are confident that their effects will be positive and their risks will be manageable.
This pause should be public and verifiable, and include all key actors. If such a pause cannot be enacted quickly, governments should step in and institute a moratorium.
AI labs and independent experts should use this pause to jointly develop and implement a set of shared safety protocols for advanced AI design and development that are rigorously audited and overseen by independent outside experts. These protocols should ensure that systems adhering to them are safe beyond a reasonable doubt. This does not mean a pause on AI development in general, merely a stepping back from the dangerous race to ever-larger unpredictable black-box models with emergent capabilities.
If we look away from the fact that it's currently impossible to know what 'stronger than GPT-4' actually means (because OpenAI don't disclose information on their model training nor make code available to the world), there are other, bigger problems at hand.
Eliezer Yudkowsky quickly wrote an open letter in response13. From the letter:
I refrained from signing because I think the letter is understating the seriousness of the situation and asking for too little to solve it.
[...]
To visualize a hostile superhuman AI, don’t imagine a lifeless book-smart thinker dwelling inside the internet and sending ill-intentioned emails. Visualize an entire alien civilization, thinking at millions of times human speeds, initially confined to computers—in a world of creatures that are, from its perspective, very stupid and very slow. A sufficiently intelligent AI won’t stay confined to computers for long. In today’s world you can email DNA strings to laboratories that will produce proteins on demand, allowing an AI initially confined to the internet to build artificial life forms or bootstrap straight to postbiological molecular manufacturing.
If somebody builds a too-powerful AI, under present conditions, I expect that every single member of the human species and all biological life on Earth dies shortly thereafter.
Even if we believe Yudkowsky to be Cassandra14, there's another problem with the modern AI systems.
Sayash Kapoor and Arvind Narayanan have commented20 on the open letter from the Future of Life Institute where they posit our AI problems in current time:
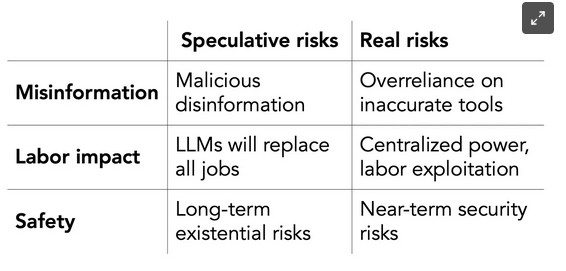
Their main points are:
- AI tools will mostly benefit capitalists (to maximise profit and subjugate workers)
- AI will spawn more misinformation than ever (due to over-reliance and automation bias, in other words, the fact that humans tend to believe AI without thorough evaluation)
- Security risks: this already exists, even without AI
The problem of belief
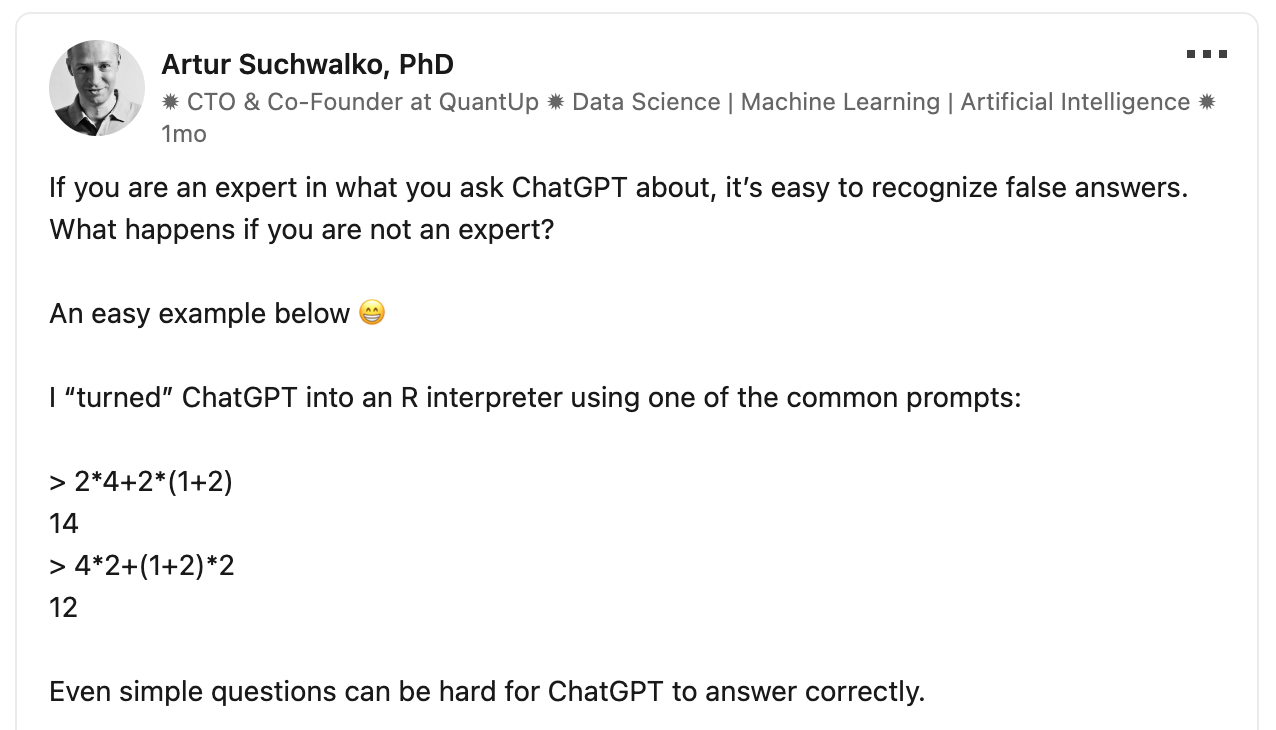 Artur Suchwalko asks ChatGPT to solve a couple of simple mathematical question18. If you're not knowledgeable enough, you won't be able to know whether ChatGPT produces fact or (potentially damaging) nonsense.
Artur Suchwalko asks ChatGPT to solve a couple of simple mathematical question18. If you're not knowledgeable enough, you won't be able to know whether ChatGPT produces fact or (potentially damaging) nonsense.
Human beings are fallible and prone to believe people who act confidently. Even though humans are (often) able to evaluate and contest statements, a mansplainer can get their way by bulldozing stupid things into our minds. This is what automation bias is about: we trust AI because it's convincing and often a con person.
From Adam Kaczmarek's blog post15
Even taking into account the learning with human feedback, ChatGPT is still a parrot repeating what it saw on the internet with additional Bullshit-generation capabilities. There is no way a model trained simply on the objective of learning how the language looks like is able to do much more than repeat information (in a way aligned to user query) that it already saw during training as it has little to none understanding of the contents. Human feedback only adds another layer of deception, providing the model information on how people like the bullshit to be served.
The fact that OpenAI allegedly tried to hire people to play with and explain in extensive detail how to solve various problems only proves that simply making a model bigger does not mean it becomes smarter. It just has more storage for memorizing the answers.
Noam Chomsky, Ian Roberts, and Jeffrey Watumull recently wrote an article on what ChatGPT (and similar models) are not able to do16. From the article:
[...] ChatGPT and similar programs are, by design, unlimited in what they can “learn” (which is to say, memorize); they are incapable of distinguishing the possible from the impossible. Unlike humans, for example, who are endowed with a universal grammar that limits the languages we can learn to those with a certain kind of almost mathematical elegance, these programs learn humanly possible and humanly impossible languages with equal facility. Whereas humans are limited in the kinds of explanations we can rationally conjecture, machine learning systems can learn both that the earth is flat and that the earth is round. They trade merely in probabilities that change over time.
For this reason, the predictions of machine learning systems will always be superficial and dubious. Because these programs cannot explain the rules of English syntax, for example, they may well predict, incorrectly, that “John is too stubborn to talk to” means that John is so stubborn that he will not talk to someone or other (rather than that he is too stubborn to be reasoned with). Why would a machine learning program predict something so odd? Because it might analogize the pattern it inferred from sentences such as “John ate an apple” and “John ate,” in which the latter does mean that John ate something or other. The program might well predict that because “John is too stubborn to talk to Bill” is similar to “John ate an apple,” “John is too suborn to talk to” should be similar to “John ate.” The correct explanations of language are complicated and cannot be learned just by marinating in big data.
Perversely, some machine learning enthusiasts seem to be proud that their creations can generate correct “scientific” predictions (say, about the motion of physical bodies) without making use of explanations (involving, say, Newton’s laws of motion and universal gravitation). But this kind of prediction, even when successful, is pseudoscience. While scientists certainly seek theories that have a high degree of empirical corroboration, as the philosopher Karl Popper noted, “we do not seek highly probable theories but explanations; that is to say, powerful and highly improbable theories.”
The article includes examples of Dr. Watamull interacting with ChatGPT. The examples show what Hannah Arendt called the banality of evil: plagiarism, apathy, and obviation, to quote from the article.
In summary
ChatGPT is an automated mansplaining machine: often wrong, yet always certain17. Other AI systems are similar in nature: while they can mimic a human being at this point in time, trusting a model like ChatGPT would be silly at best. This also goes for AI image generators: do you know the image you just generated is original and could be sold without getting sued for breaking copyright laws?
You wouldn't trust a human automated mansplainer, so why would you trust ChatGPT? Why use DALL-E 2 to make you generative art that's illegally trained on copyrighted art?
If you're a developer, your manager and colleagues would call you out if you stole their code; do this repeatedly and you'd probably get fired. Naturally, developers copy code from places like Stack Overflow, but tech like Microsoft Copilot is trained using stolen code19 and offers it straight back to you:
The Software Freedom Conservancy (SFC), a non-profit community of open-source advocates, today announced its withdrawal from GitHub in a scathing blog post urging members and supporters to rebuke the platform once-and-for-all.
Up front: The SFC’s problem with GitHub stems from accusations that Microsoft and OpenAI trained an AI system called Copilot on data that was published under an open-source license.
Open-source code isn’t like a donations box where you can just take whatever you want and use it in any way you choose.
It’s more like photography. Just because a photographer doesn’t charge you to use one of their images, you’re still ethically and legally required to give credit where it’s due.
Remember the films 2001: A Space Odyssey and Terminator 2 where technology became self-aware and attacked humans? They're fiction. But what Yudkowsky describes isn't impossible. In fact, it's quite possible. Especially when we have no safeguards in place and a company like OpenAI, one that steals data and hires people for two USD/hour to look thorugh despicable things, are in control, keeping their methods and code behind closed walls.
Consider the man who committed suicide after a six-week conversation with an AI chatbot that encouraged him to kill himself21. Automated suicide.
Imagine what would happen if governments prevented companies from creating software that could do those things. We could have a flourishing society where AI helps us and doesn't shower us in misinformation, works as tools-for-profit, or suddenly decide to kill us all.
That is possible to do. Contact your local politicians. Join the EFF. Fight what can be done against us for profit.
-
Future of Life Institute. ‘Pause Giant AI Experiments: An Open Letter’. Accessed 31 March 2023. https://futureoflife.org/open-letter/pause-giant-ai-experiments/. ↩
-
Twitter. ‘Open AI Is Stealing Your Data and Profiting from It. ChatGPT Admits It Is Using Data That It Doesn’t Have the Rights to.’ Accessed 31 March 2023. https://twitter.com/minds/status/1628418895563440139. ↩
-
‘Large Language Model’. In Wikipedia, 29 March 2023. https://en.wikipedia.org/w/index.php?title=Large_language_model&oldid=1147211272. ↩
-
Xiang, Chloe. ‘OpenAI Is Now Everything It Promised Not to Be: Corporate, Closed-Source, and For-Profit’. Vice (blog), 28 February 2023. https://www.vice.com/en/article/5d3naz/openai-is-now-everything-it-promised-not-to-be-corporate-closed-source-and-for-profit. ↩
-
Perrigo, Billy. ‘OpenAI Used Kenyan Workers on Less Than $2 Per Hour to Make ChatGPT Less Toxic’. Time, 18 January 2023. https://time.com/6247678/openai-chatgpt-kenya-workers/. ↩
-
Weprin, Alex. ‘Want to Impress Wall Street? Just Add Some AI’. The Hollywood Reporter (blog), 8 March 2023. https://www.hollywoodreporter.com/business/business-news/wall-street-ai-stock-price-1235343279/. ↩
-
Witte, Melissa de. ‘Why “Copycat” Layoffs Won’t Help Tech Companies — Or Their Employees’. Stanford Graduate School of Business, 24 October 2022. https://www.gsb.stanford.edu/insights/why-copycat-layoffs-wont-help-tech-companies-or-their-employees. ↩
-
Zuboff, Shoshana. The Age of Surveillance Capitalism: The Fight for a Human Future at the New Frontier of Power. London: Profile books, 2019. ↩
-
‘Surveillance Capitalism’. In Wikipedia, 31 March 2023. https://en.wikipedia.org/w/index.php?title=Surveillance_capitalism&oldid=1147544226. ↩
-
‘Cambridge Analytica’. In Wikipedia, 23 March 2023. https://en.wikipedia.org/w/index.php?title=Cambridge_Analytica&oldid=1146248522. ↩
-
Lee, Timothy B. ‘Stable Diffusion Copyright Lawsuits Could Be a Legal Earthquake for AI’. Ars Technica, 3 April 2023. https://arstechnica.com/tech-policy/2023/04/stable-diffusion-copyright-lawsuits-could-be-a-legal-earthquake-for-ai/. ↩
-
Vincent, James. ‘The Lawsuit That Could Rewrite the Rules of AI Copyright’. The Verge, 8 November 2022. https://www.theverge.com/2022/11/8/23446821/microsoft-openai-github-copilot-class-action-lawsuit-ai-copyright-violation-training-data. ↩
-
: Yudkowsky, Eliezer. ‘Pausing AI Developments Isn’t Enough. We Need to Shut It All Down’. Time, 29 March 2023. https://time.com/6266923/ai-eliezer-yudkowsky-open-letter-not-enough/. ↩
-
‘Cassandra’. In Wikipedia, 11 March 2023. https://en.wikipedia.org/w/index.php?title=Cassandra&oldid=1143972880#Gift_of_prophecy. ↩
-
Kaczmarek, Adam. ‘ChatGPT - The Revolutionary Bullshit Parrot’. Accessed 3 April 2023. https://www.reasonfieldlab.com/post/chatgpt-the-revolutionary-bullshit-parrot. ↩
-
Chomsky, Noam, Ian Roberts, and Jeffrey Watumull. ‘Opinion | Noam Chomsky: The False Promise of ChatGPT’. The New York Times, 8 March 2023, sec. Opinion. https://www.nytimes.com/2023/03/08/opinion/noam-chomsky-chatgpt-ai.html. ↩
-
Harrison, Maggie. ‘ChatGPT Is Just an Automated Mansplaining Machine’. Futurism. Accessed 3 April 2023. https://futurism.com/artificial-intelligence-automated-mansplaining-machine. ↩
-
‘Artur Suchwalko, PhD on LinkedIn: AI ChatGPT’. Accessed 3 April 2023. https://www.linkedin.com/posts/artursuchwalko_ai-chatgpt-activity-7034472289706356736-G0u6. ↩
-
Greene, Tristan. ‘Copilot Works so Well Because It Steals Open Source Code and Strips Credit’. TNW | Deep-Tech, 1 July 2022. https://thenextweb.com/news/github-copilot-works-so-well-because-it-steals-open-source-code-strips-credit. ↩
-
Kapoor, Sayash, and Arvind Narayanan. ‘A Misleading Open Letter about Sci-Fi AI Dangers Ignores the Real Risks’. Substack newsletter. AI Snake Oil (blog), 29 March 2023. https://aisnakeoil.substack.com/p/a-misleading-open-letter-about-sci. ↩
-
Atillah, Imane El. ‘AI Chatbot Blamed for “encouraging” Young Father to Take His Own Life’. euronews, 31 March 2023. https://www.euronews.com/next/2023/03/31/man-ends-his-life-after-an-ai-chatbot-encouraged-him-to-sacrifice-himself-to-stop-climate-. ↩